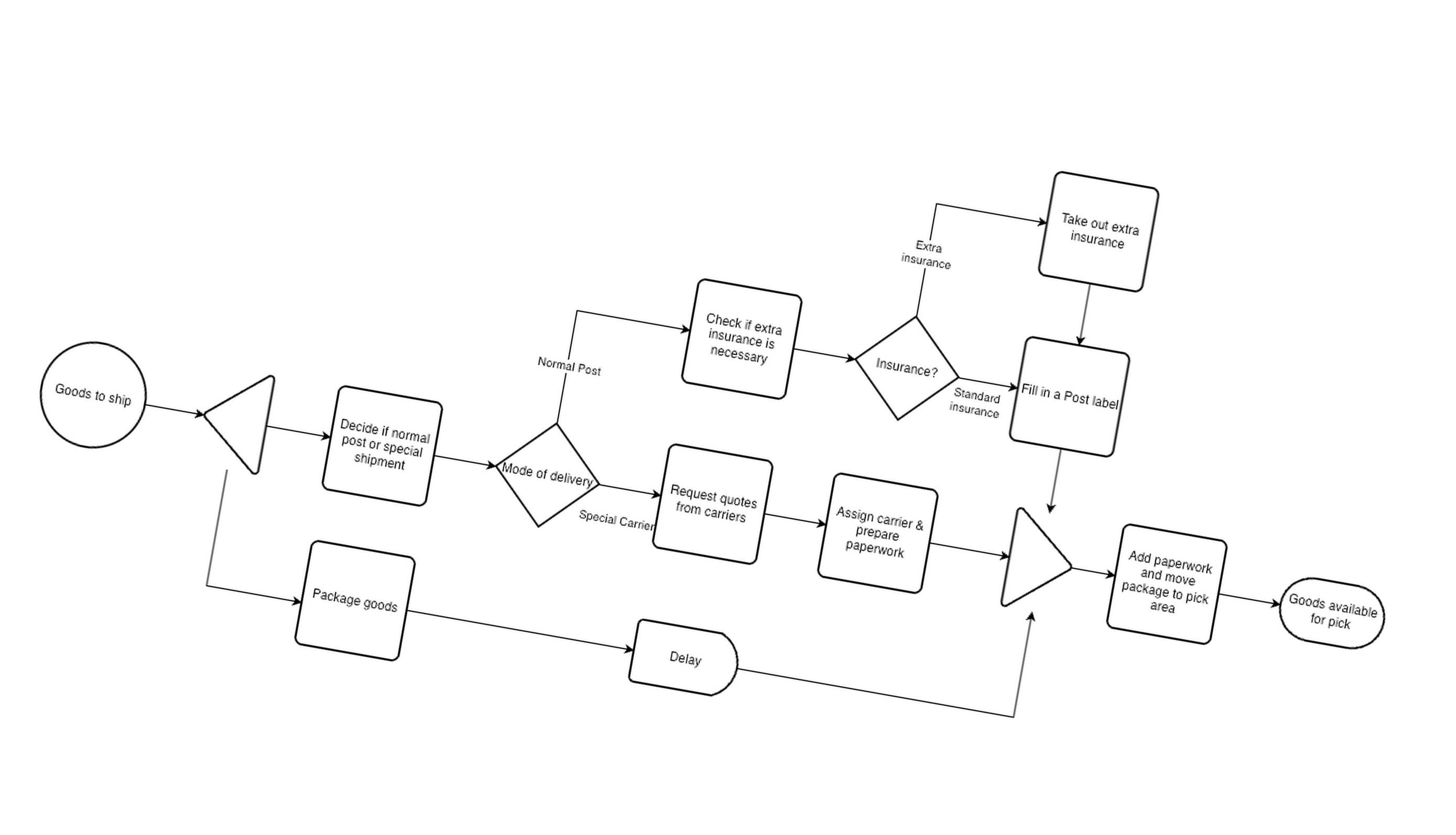
The engine supports a carefully chosen subset of draw.io's flowchart shapes. Each node type maps to a specific execution behaviour.
mxgraph.flowchart.start_1 / start_2
Start
Entry point of the workflow. Can carry default context values as custom properties. If context is passed by a parent workflow, start node values act as defaults only — they never overwrite inherited context.
mxgraph.flowchart.terminator
End
Terminal node. When reached, the workflow is marked completed. Its final context contains all key-value pairs accumulated across every executed node.
Shape: label (rounded rectangle)
Process
The workhorse node. Merges fixed key-value pairs into the workflow context, or calls an external REST API (type: rest) and optionally waits for the response in blocking or scheduled mode.
Shape: process (double-bar rectangle)
Predefined Process
Invokes another .drawio model as an independent sub-workflow. The parent passes its current context to the child and waits for completion before continuing.
mxgraph.flowchart.decision
Decision
Routes execution based on a context variable. Each outgoing connector carries a label matching an expected context value. If no connector matches, execution stops with an error. Supports wildcard routing.
Extract
Splits a single flow into parallel branches. By default, branches run as concurrent threads within the same request. When ENGINE_URL is set, each branch is dispatched as an independent HTTP child request.
mxgraph.flowchart.merge_or_storage
Merge
Rejoins parallel branches. Execution waits until all sibling branches have completed. Context from all branches is merged before the flow continues to subsequent nodes.
Shape: manualinput
Manual Input
Pauses the workflow and waits for an external action. The engine writes a manual_input_*.json file. When its status is set to completed and values added to input_data, the next run resumes from this point.
mxgraph.flowchart.delay
Delay
Pauses execution for a configured duration (delay: 30s / 5m / 2h / 1d). In blocking mode the request is held open; in scheduled mode the engine returns immediately and awaits an external resume call.